
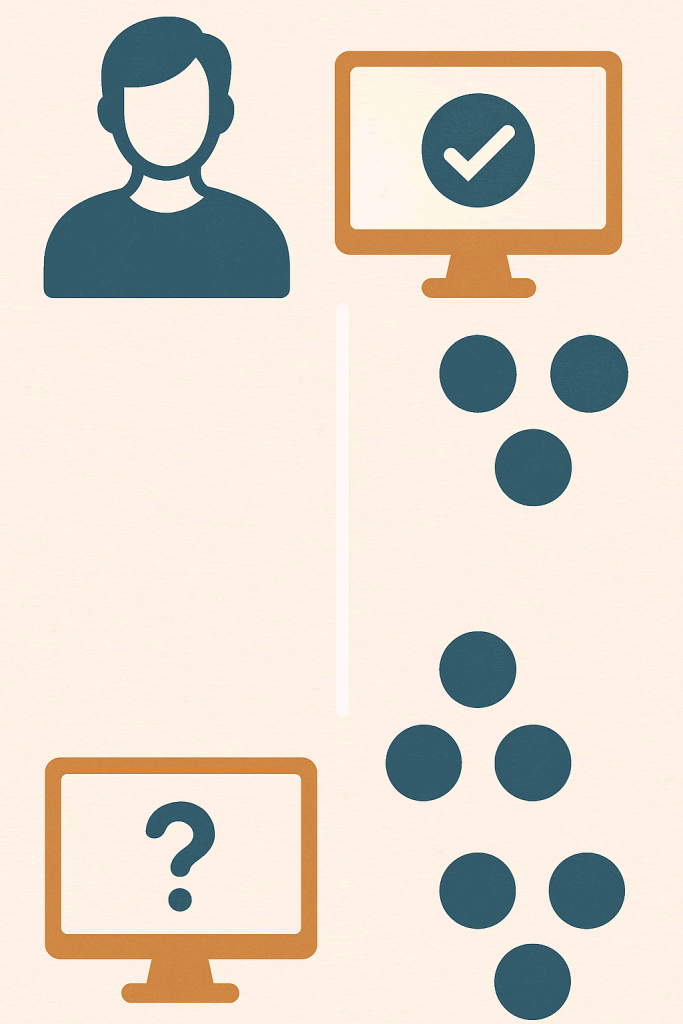

Supervised and unsupervised learning are two fundamental approaches within machine learning, and each serves a different purpose depending on the kind of data available and the goal of the system. At AEHEA, we work with both methods depending on the problem we’re solving. The key difference lies in whether the algorithm has access to labeled data that is, whether the correct answers are provided during training.
In supervised learning, the algorithm is trained on a dataset that includes both inputs and the corresponding correct outputs. Think of it like teaching a child with flashcards we show the system what a correct answer looks like, then let it learn patterns that connect input to output. This approach is ideal for tasks like spam detection, image classification, and sentiment analysis. It’s precise and effective when labeled data is available, but it requires a lot of preparation to ensure that training examples are clean, accurate, and representative.
Unsupervised learning, on the other hand, deals with input data that has no labeled outcomes. The system is asked to identify patterns, groupings, or structures within the data on its own. This is useful for tasks like customer segmentation, anomaly detection, or organizing large sets of documents. Here, we’re not giving the model the “right” answers. Instead, we let it discover relationships that might not be obvious at first glance. While it requires less upfront labeling, the results often need more interpretation and validation to make them actionable.
From our experience at AEHEA, supervised learning is great for solving clearly defined problems where you know what success looks like. Unsupervised learning is more exploratory and useful when trying to understand a new dataset or uncover hidden patterns. Often, we combine the two using unsupervised techniques to explore the data, then applying supervised models once we’ve defined the right outcomes. Both approaches are powerful tools when matched to the right task, and they form the foundation of most AI systems we build or deploy.