
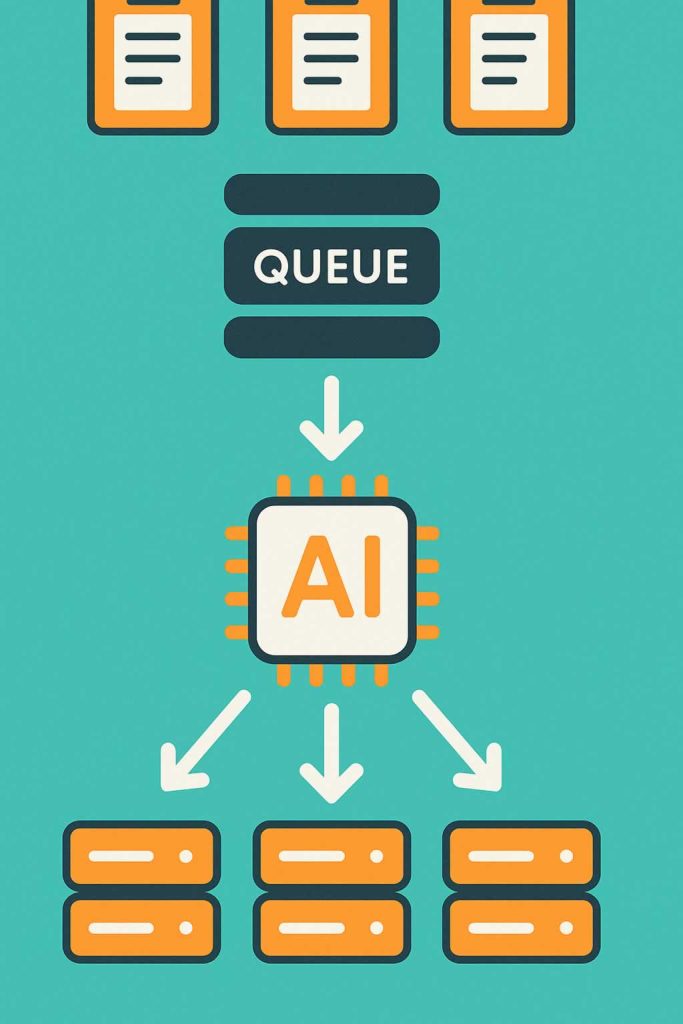
Handling AI job queuing and scaling is essential when your models need to serve multiple users or process large volumes of data efficiently. Without proper queuing and scaling, systems can become overloaded, slow, or unreliable. At AEHEA, we design AI infrastructures with these needs in mind from the very beginning. Whether it’s a chatbot that receives thousands of messages or a model that processes incoming documents around the clock, job handling has to be predictable and resilient.
Job queuing is about organizing tasks, so they are processed in an orderly, manageable fashion. We often use message queues like RabbitMQ, Redis Queue, or Amazon SQS to manage incoming jobs. These systems hold tasks in a queue and distribute them to workers as resources become available. That way, if the model is already busy or the server is at capacity, tasks are not lost. They wait their turn and are processed in sequence. This prevents bottlenecks and makes workloads more predictable, especially when paired with retry policies and error tracking.
Scaling is the next layer. Once a queue system is in place, you need the infrastructure to handle increased demand. That’s where we use containers and orchestration tools like Docker and Kubernetes. These allow us to spin up multiple instances of a model or worker process as needed. If traffic spikes, the system can automatically add more capacity. If demand drops, it scales back down to save resources. This elasticity is especially important for businesses that face variable workloads or operate across time zones.
At AEHEA, our priority is always stability and responsiveness. We design queues with timeouts, priorities, and failure recovery. We scale infrastructure based on metrics like CPU usage, request volume, and latency. By doing this, we ensure that AI systems don’t just function they perform under pressure. With a thoughtful approach to queuing and scaling, AI moves from a promising prototype to a production ready engine that delivers results at any volume.